文章目录
一、概念
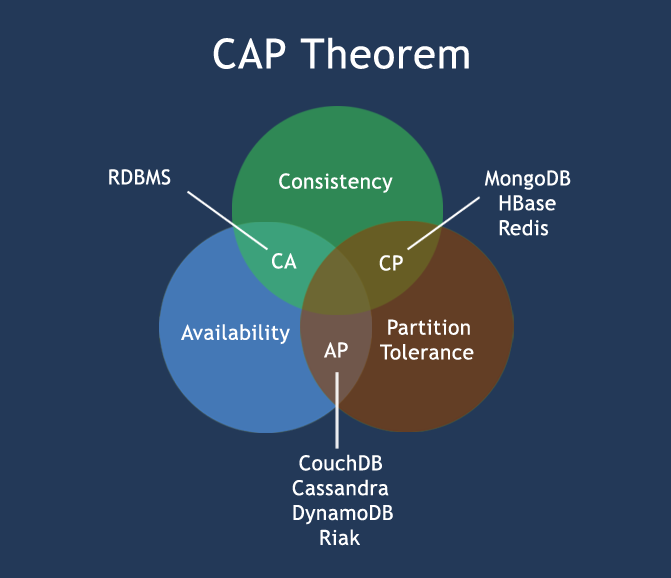
1、CAP定律
Consistency(一致性): 数据一致更新,针对集群内所有节点数据变动都是同步完成。
Availability(可用性): 在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。
Partition tolerance(分区容错性): 以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
It states, that though its desirable to have Consistency, High-Availability and Partition-tolerance in every system, unfortunately no system can achieve all three at the same time.
在分布式系统的设计中,没有一种设计可以同时满足一致性,可用性,分区容错性 3个特性
2、ACID模型
Atomicity(原子性): 事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
Consistency(一致性): 事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
Isolation(隔离性): 多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
Durability(持久性): 一个事务一旦提交,他对数据库的修改应该永久保存在数据库中。
3、BASE模型(反ACID模型)
Basically Available(基本可用): 基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。
Soft state(软状态): 软状态和硬状态相对,是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,数据更改时允许集群的不同节点有一段时间进行数据状态同步。
Eventually consistent(最终一致性): 事务处理过程中,会有短暂不一致的情况,但通过恢复系统,可以让事务的数据达到最终一致的目标。
二、强一致性解决方案
1、2PC (二阶段提交)
算法思路: 参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作。
XA协议: XA是一个分布式事务协议,由Tuxedo提出。XA中大致分为两部分:事务管理器(Transaction Manager)和本地资源管理器(Local Resource Manager)。其中本地资源管理器往往由数据库实现,比如Oracle、DB2这些商业数据库都实现了XA接口,而事务管理器作为全局的调度者,负责各个本地资源的提交和回滚。
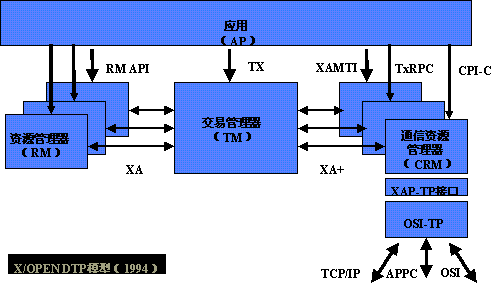
二阶段:
- 准备阶段: 事务协调者(事务管理器)给每个参与者(资源管理器)发送Prepare消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的redo和undo日志,但不提交本地事务。
- 提交阶段: 如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。(注意:必须在最后阶段释放锁资源)
缺点:
- 同步阻塞问题。执行过程中,所有参与节点都是事务阻塞型的。当参与者占有公共资源时,其他第三方节点访问公共资源不得不处于阻塞状态。
- 单点故障。由于协调者的重要性,一旦协调者发生故障。参与者会一直阻塞下去。尤其在第二阶段,协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,而无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
- 数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
- 二阶段无法解决的问题:协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
2、3PC (三阶段提交)
与两阶段提交不同的是,三阶段(CanCommit、PreCommit、DoCommit)提交有两个改动点:
- 引入超时机制。同时在协调者和参与者中都引入超时机制。
- 在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
CanCommit阶段: 3PC的CanCommit阶段其实和2PC的准备阶段很像。协调者向参与者发送commit请求,参与者如果可以提交就返回Yes响应,否则返回No响应。
PreCommit阶段: 协调者根据参与者的反应情况来决定是否可以继续事务的PreCommit操作。如果参与者执行完本地事务操作则返回YES,假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断。
doCommit阶段: 该阶段由协调者通知参与者的PreCommit阶段反馈进行判断,最终决定是真正的事务提交,还是执行事务回滚。
缺点:
在doCommit阶段,如果参与者无法及时接收到来自协调者的doCommit或者rebort请求时,会在等待超时之后,会继续进行事务的提交。(其实这个应该是基于概率来决定的,当进入第三阶段时,说明参与者在第二阶段已经收到了PreCommit请求,那么协调者产生PreCommit请求的前提条件是他在第二阶段开始之前,收到所有参与者的CanCommit响应都是Yes。(一旦参与者收到了PreCommit,意味他知道大家其实都同意修改了)所以,一句话概括就是,当进入第三阶段时,由于网络超时等原因,虽然参与者没有收到commit或者abort响应,但是他有理由相信:成功提交的几率很大。 )
3、Paxos算法
待补充
三、最终一致性解决方案
1、本地消息表
设计思想: 是将远程分布式事务拆分成一系列的本地事务。借助关系型数据库中的表即可实现。
集群节点同步: 定时扫描本地消息表,将需要同步状态的消息产生MQ消息通过向时效性高的MQ放入消息,再由其它集群节点消费该消息完成通知,通过消息消费状态表来避免MQ消息的重复消费。
2、RocketMQ(事务消息)
以网传处理流程为例进行说明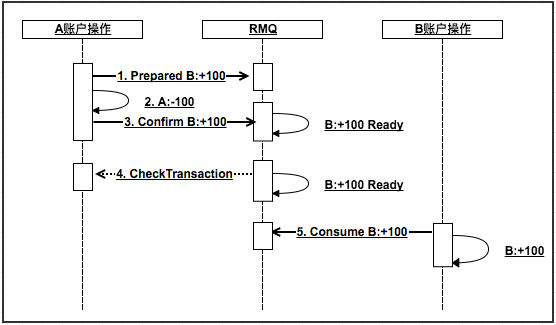
说明:
1、当第3步confirmB失败时,则交由RMQ定时调用checkTransaction进行处理结果的检测,如果为失败,则rollback,否则发送消息到B账户。
2、当第5步consumeB失败时,则交由RMQ定时进行重试,但需要设置最大重试次数,如果达到最大次数依然失败,则需要人工介入进行修正。
所以RMQ需要一个人工修正的控制台,当系统通过重试无法进行修正时以人工做为做终的修正手段来做保障最终事务一致性。
观点仅代表自己,期待你的留言。