boolean registerOK = mQClientFactory.registerProducer(this.defaultMQProducer.getProducerGroup(), this); if (!registerOK) { this.serviceState = ServiceState.CREATE_JUST; thrownew MQClientException("The producer group[" + this.defaultMQProducer.getProducerGroup() + "] has been created before, specify another name please." + FAQUrl.suggestTodo(FAQUrl.GROUP_NAME_DUPLICATE_URL), null); }
this.topicPublishInfoTable.put(this.defaultMQProducer.getCreateTopicKey(), new TopicPublishInfo());
if (startFactory) { mQClientFactory.start(); }
log.info("the producer [{}] start OK. sendMessageWithVIPChannel={}", this.defaultMQProducer.getProducerGroup(), this.defaultMQProducer.isSendMessageWithVIPChannel()); this.serviceState = ServiceState.RUNNING; break; case RUNNING: case START_FAILED: case SHUTDOWN_ALREADY: thrownew MQClientException("The producer service state not OK, maybe started once, "// + this.serviceState// + FAQUrl.suggestTodo(FAQUrl.CLIENT_SERVICE_NOT_OK), null); default: break; }
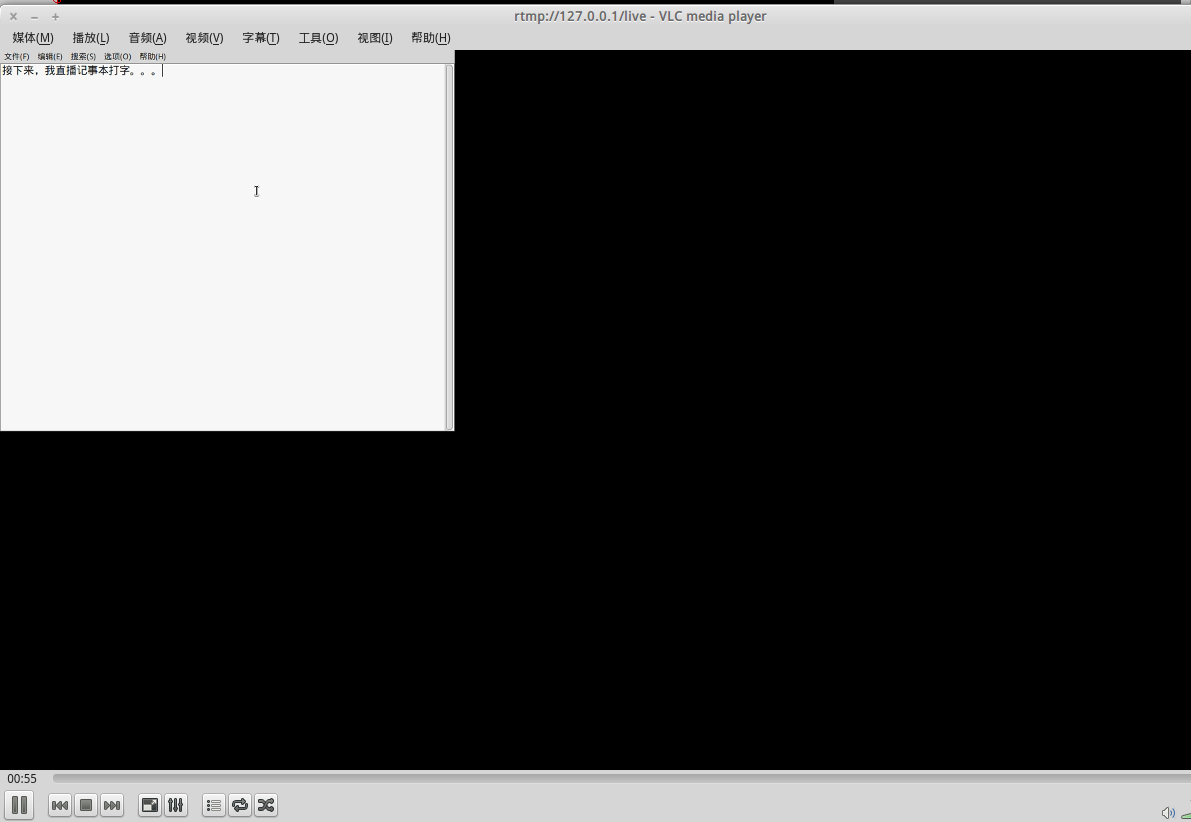
wujianjun@wujianjun-work ~ $ uname -a Linux wujianjun-work 4.10.0-37-generic #41~16.04.1-Ubuntu SMP Fri Oct 6 22:42:59 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
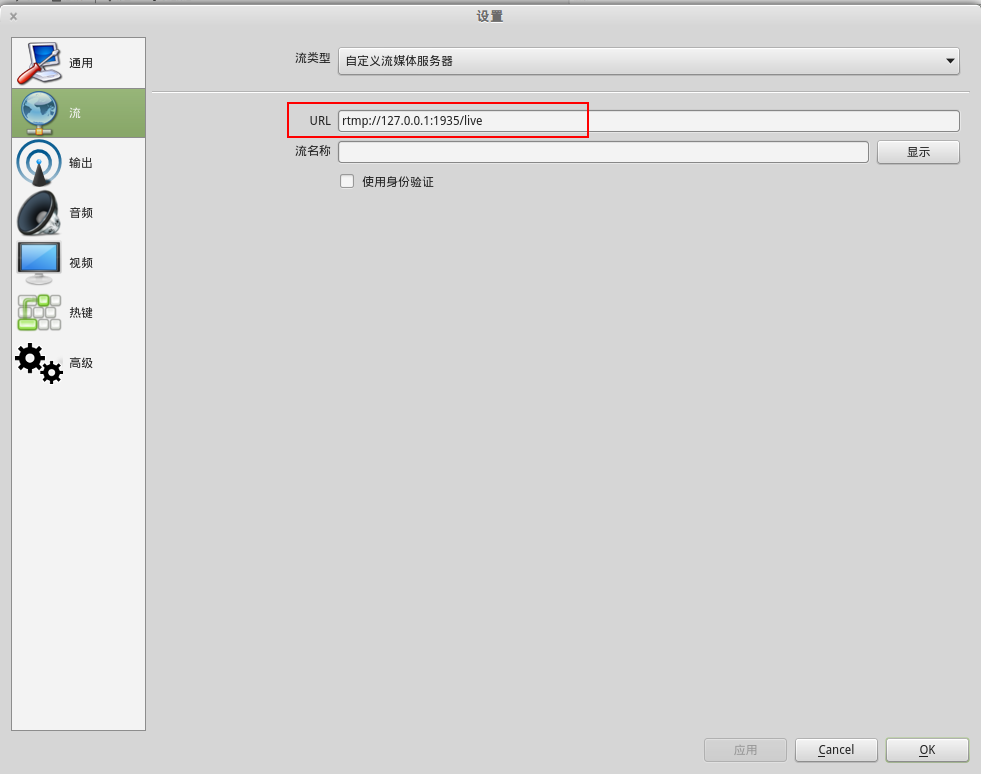
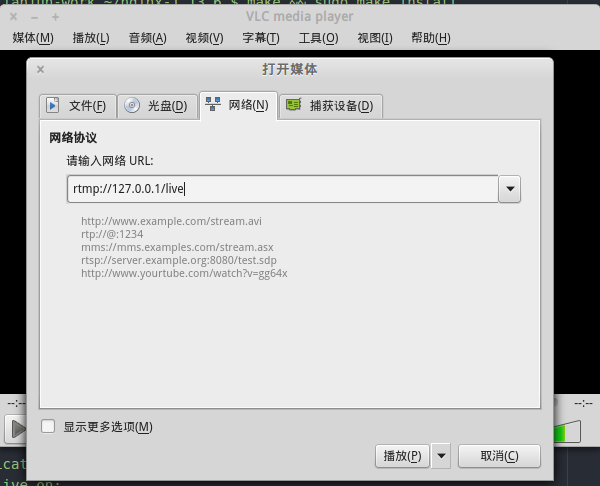
nginx version: nginx/1.13.6 built by gcc 5.4.0 20160609 (Ubuntu 5.4.0-6ubuntu1~16.04.5) built with OpenSSL 1.0.2g 1 Mar 2016 TLS SNI support enabled configure arguments: –with-pcre=pcre-8.38 –add-module=nginx-rtmp-module-1.1.11
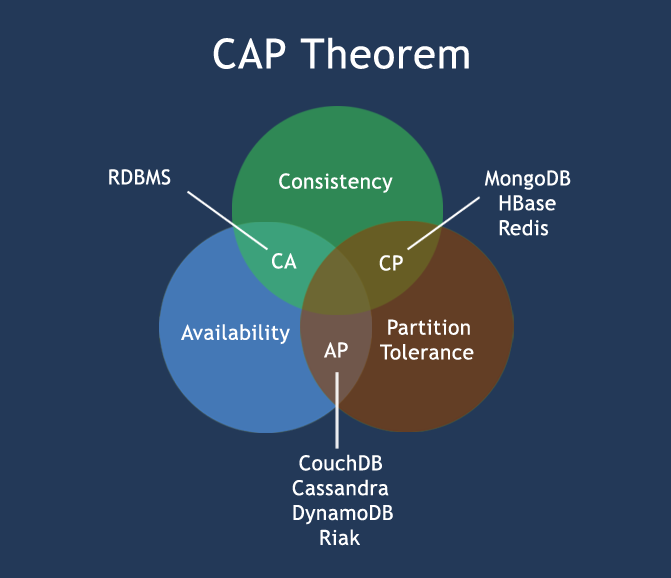
It states, that though its desirable to have Consistency, High-Availability and Partition-tolerance in every system, unfortunately no system can achieve all three at the same time. 在分布式系统的设计中,没有一种设计可以同时满足一致性,可用性,分区容错性 3个特性