简介
最近整理的中国全国城市数据库信息,共享于网络。
观点仅代表自己,期待你的留言。
在web 项目中(spring mvc),系统会存在两个容器,一个是ApplicationContext,另一个就是我们自己的WebApplicationContext(作为ApplicationContext的子容器)。
WebApplicationContext通过getParent()获取到ApplicationContext,而ApplicationContext的getParent()将获取到null(ApplicationContext没有父容器)。
InitializingBean表示为spring管理的初始类,当Bean初始时进行属性注入完成后调用afterPropertiesSet进行初始处理。( 趟坑笔记 add by 2017-07-18)
FactoryBean 是创建 复杂的bean,一般的bean 直接用xml配置即可,如果一个bean的创建过程中涉及到很多其他的bean 和复杂的逻辑,用xml配置比较困难,这时可以考虑用FactoryBean。
spring配置时会自动调用getObject来获取注入对象。
@see org.springframework.web.accept.ContentNegotiationManagerFactoryBean
ApplicationListener用于监听应用程序的事件。
所包含的事件详见ApplicationEvent子类。
当Application事件发生时会自动调用监听器的onApplicationEvent方法。
ApplicationContextAware用于用户保存ApplicationContext的引用,供客户端程序获取ApplicationContext时使用。
DisposableBean用于标识可销毁的类,当类进行回收时调用destroy()
观点仅代表自己,期待你的留言。
通过近期的努力,将编写的源代码生成器进行0.0.1版本的封版,代码生成器按数据表自动生成源代码包含简单业务的(增,删,改,查,分页等)。
部分集成的开源框架已通过配置文件进行开关配置,方便按业务进行开启和关闭。欢迎大家使用。
Github地址:https://github.com/stotem/GGCode
源代码生成框架: rapid-framework
UI框架: sb-admin-2
代码框架: SpringMVC + mybatis + Velocity。
代码架构: 经典三层架构(MVC), 增加rpc模块做为调用三方api模块, 增加manager模块设置为缓存层与事务层。
主要转换规则:
在bin目录中通过配置generator.xml后直接java -jar GGCode-0.0.1.jar
详见generator.xml注释
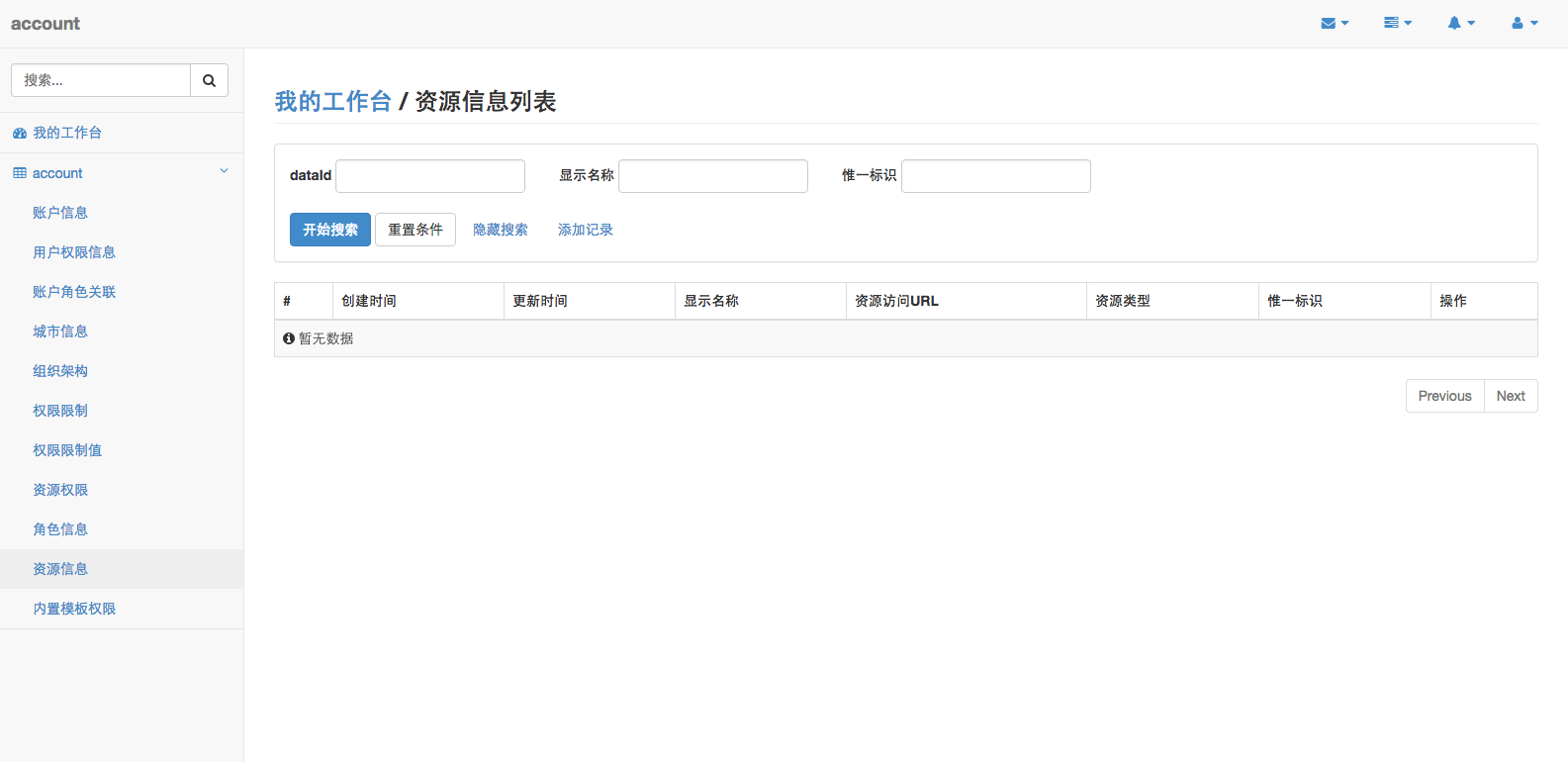
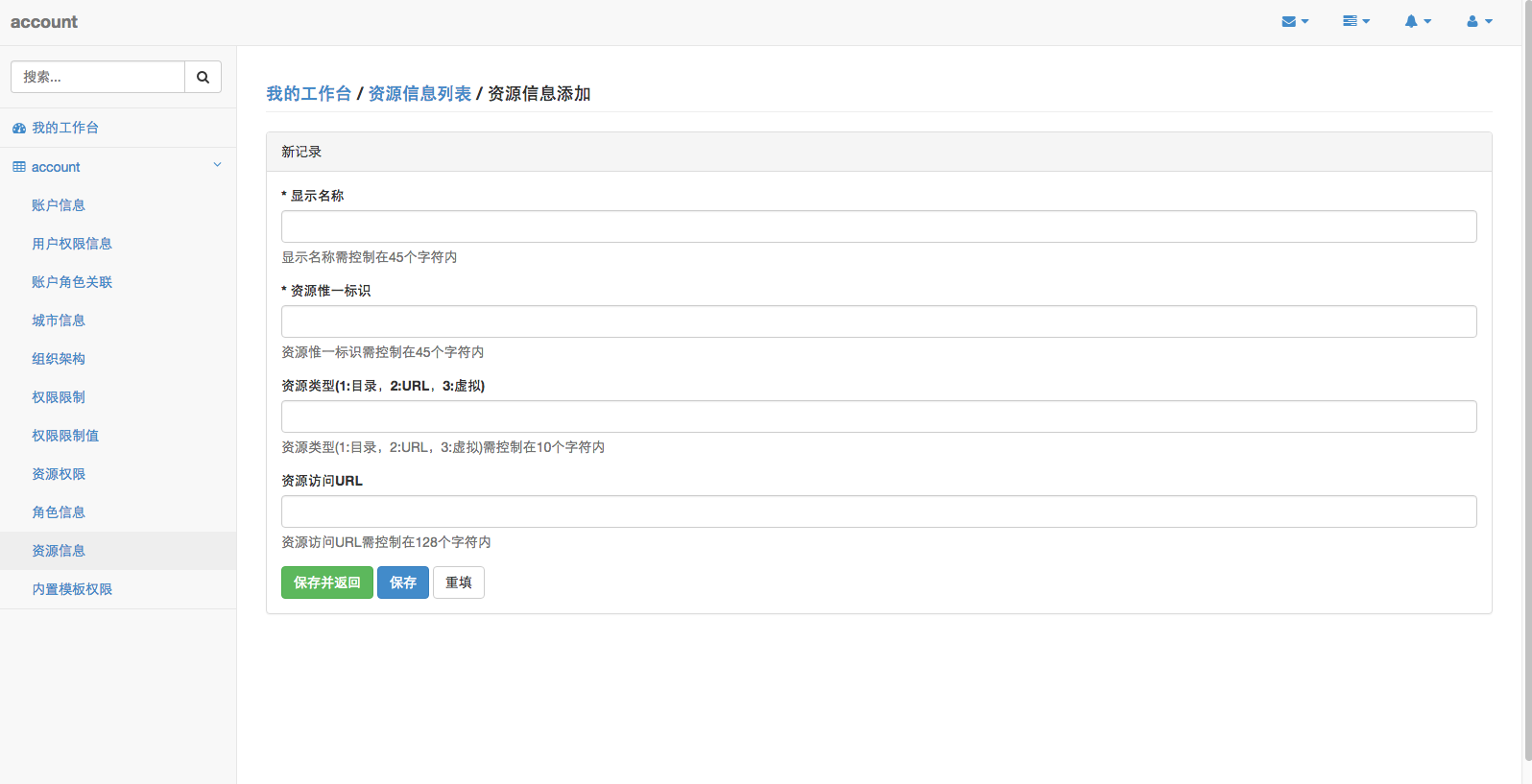
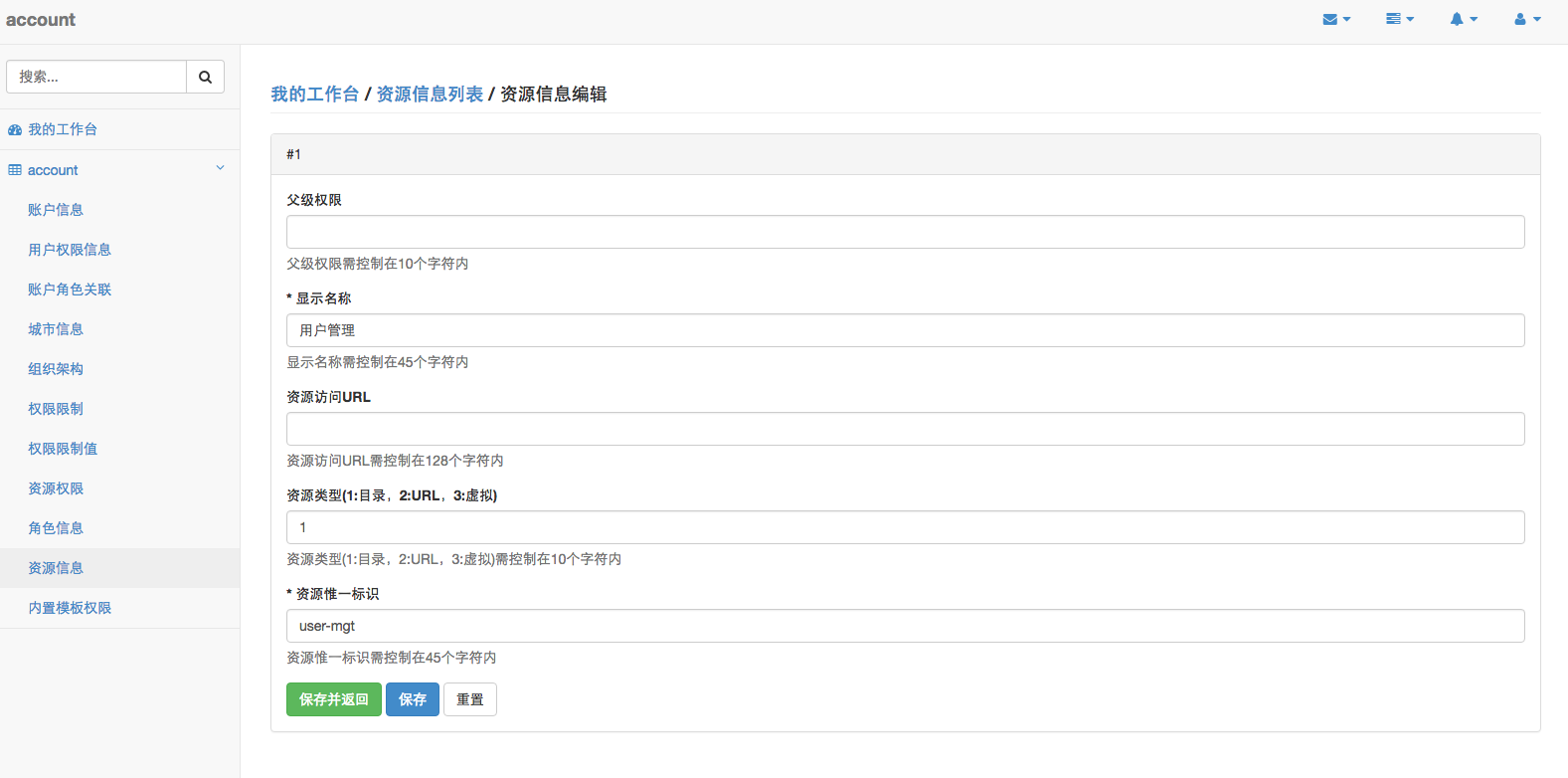
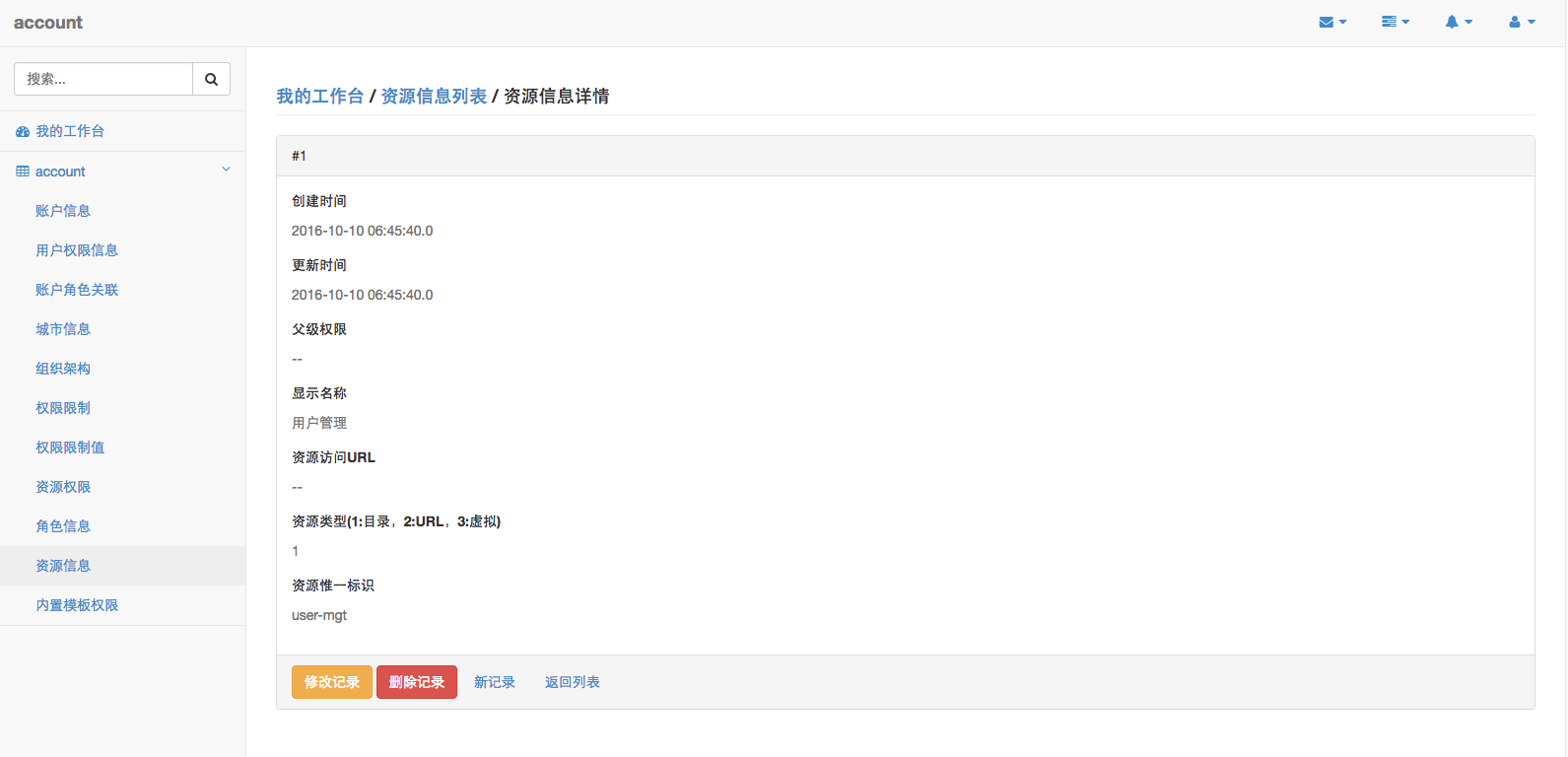
为了规范生成的Code,针对数据表的设计,需要满足每张表包含以下字段,请使用者遵守:
1 | data_id bigint PRIMARY KEY COMMENT '数据主键(与业务主键区分)', |
观点仅代表自己,期待你的留言。
Shiro是apache开源项目,主要用户客户端管理登录用户权限提示非常方式的认证接口及丰富的注解。
CAS ( Central Authentication Service )是Yale大学发起的一个企业级的、开源的项目,旨在为 Web 应用系统提供一种可靠的单点登录解决方案(属于Web SSO)。主要用于用户登录认证与登录有效期认证。

观点仅代表自己,期待你的留言。
介绍网址: https://github.com/apereo/cas
github地址:https://github.com/apereo/cas.git
默认情况下,当用户认证成功后,客户端代码中只能获取到用户的登录名称,不能获取到其它的信息(如:手机号,所属角色,已有授权等),好在提供了一个attribute的map可以进行其它信息的返回。
1 | AttributePrincipal ap = AssertionHolder.getAssertion().getPrincipal(); |
找到WEB-INF/view/jsp/protocol/2.0/casServiceValidationSuccess.jsp,在节点之前添加以下内容。
1 | <cas:serviceResponse xmlns:cas='http://www.yale.edu/tp/cas'> |
在deployerConfigContext.xml配置文件中,默认采用AcceptUsersAuthenticationHandler类的users属性(以key为登录名value为密码)进行系统用户的设定。
而通过PersonDirectoryPrincipalResolver的attributeRepository属性进行attribute映射和配置。默认由NamedStubPersonAttributeDao类的backingMap属性进行key-value配置,针对所有的用户都生效。
提示:IPersonAttributeDao有很多的子类实现,可以通过源码查看各自实现的方式,我这里主要介绍json,xml和数据库三种方式实现。
而在实际业务系统设计中针对不同的用户需要返回不同的attribute这个需求似乎不太适用,经过查看可能配置JsonBackedComplexStubPersonAttributeDao来在json中针对单个用户attribute进行配置。指定init-method为init方法
配置如下:
1 | <bean id="attributeRepository" class="org.jasig.services.persondir.support.JsonBackedComplexStubPersonAttributeDao" init-method="init"> |
users.json
1 | { |
配置attributeRepository为XmlPersonAttributeDao来在xml中针对单个用户的attribute进行配置。
配置如下:
1 | <bean id="attributeRepository" class="org.jasig.services.persondir.support.xml.XmlPersonAttributeDao"> |
配置attributeRepository为NamedParameterJdbcPersonAttributeDao来在数据库按用户名进行attribute的配置加载。
1 | <bean id="attributeRepository" class="org.jasig.services.persondir.support.jdbc.SingleRowJdbcPersonAttributeDao"> |
在实际开发中不能任由密码明文进行传输,一般来讲会进行加密。而cas可直接通过配置的方式进行加密方式的确定。
在配置的AcceptUsersAuthenticationHandler中继承了父类中的一个名为passwordEncoder的PasswordEncoder类型属性。通过给这个属性配置加密方式值就能实现。默认为PlainTextPasswordEncoder加密方式。
如配置md5的方式:
1 | <bean id="primaryAuthenticationHandler" class="org.jasig.cas.authentication.AcceptUsersAuthenticationHandler"> |
提示:配置了密码方式之后,所有配置文件或数据库中所存储的密码则应修改为密文。
用户登录验证采用的AuthenticationHandler接口的子类实现,当我们自定义实现类完成验证时,不要妄想在通过HandlerResult的getPrincipal()获取到Principal然后给它设置attribute,因为cas在调用认证方式后会针对Principal的数据进行name的复制,所以即使你的认证方式进行了attribute的设置,在进行对象复制时也会丢掉。
详见:PolicyBasedAuthenticationManager的authenticateInternal方法中的逻辑。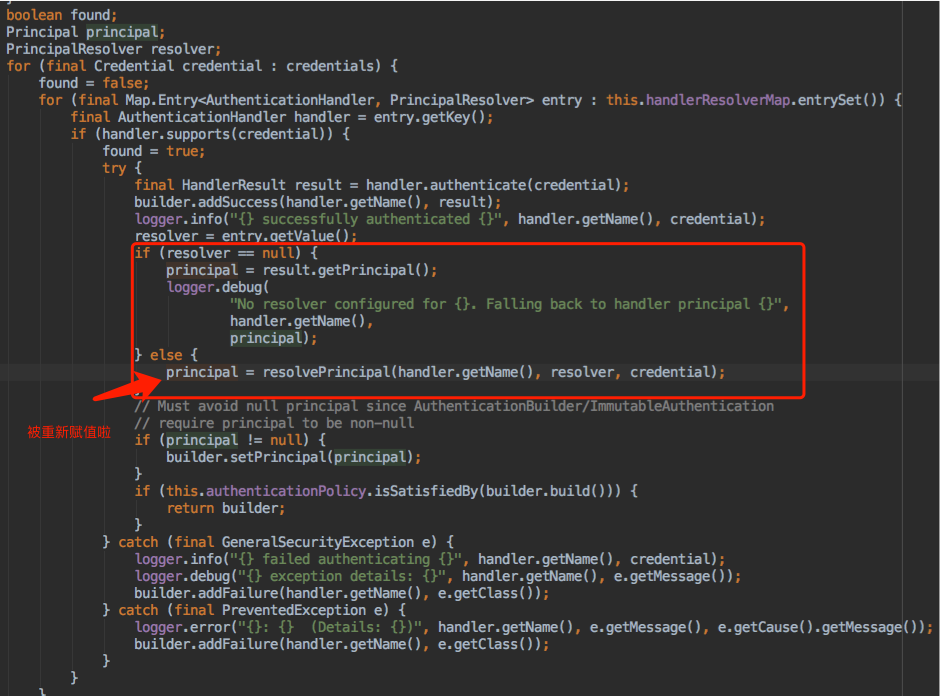
观点仅代表自己,期待你的留言。
Spring提供了@Cacheable,@CacheEvict,@CachePut等注解很方便有实现数据的缓存,而CompositeCacheManager主要用于集合多个CacheManager实例,在使用多种缓存容器时特别有用。
经过查看Spring 4.1.9.RELEASE的源码,当CompositeCacheManager的fallbackToNoOpCache属性设置为true时,CompositeCacheManager会在已配置的cacheManagers末尾添加一个NoOpCacheManager。
当通过代码中指定的缓存容器(@Cacheable等注解设置的value)没有在cacheManagers中都找到时,则会进入到NoOpCacheManager中,此时就相当于禁用掉了缓存,而不抛出相应的异常。
网络上有朋友在说,当设置fallbackToNoOpCache属性设置为true时,则可以解决缓存容器没有准备好时自动禁用缓存的效果,经过查看Spring源码,并未实现。
不过,经测试以下方法可以实现通过配置禁用缓存。
利用CompositeCacheManager + NoOpCacheManager还能解决当缓存容器没有准备好(缓存容器崩溃,网络不可用等)或者需要暂时去掉缓存的需求。
只需要将cacheManagers的list值的第一个元素设置为NoOpCacheManager就OK了。
spring.xml
1 | <bean id="cacheManager" class="org.springframework.cache.support.CompositeCacheManager"> |
观点仅代表自己,期待你的留言。
1 | public class Pagination { |
注意:输入的为闭区间(包含两端页码值)范围。
观点仅代表自己,期待你的留言。
AOP术语:
通知类型:
实例需求: 监控各Api接口执行时间,找出耗时的业务操作。
1、启用@AspectJ支持
spring.xml
1 | <beans xmlns="http://www.springframework.org/schema/beans" |
2、增加aspectj依赖库
pom.xml
1 | <dependency> |
3、编写切面类
1 | @Aspect |
对比一下xml配置
1 | <beans xmlns="http://www.springframework.org/schema/beans" |
附上测试业务实现类
1 | package org.wujianjun.apps.service.impl; |
4、测试结果
1 | 六月 30, 2016 4:11:07 下午 org.apache.coyote.AbstractProtocol start |
execution(modifiers-pattern? ret-type-pattern declaring-type-pattern? name-pattern(param-pattern)throws-pattern?)注意:切入点表达式可以使用’&’, ‘||’ 和 ‘!’来组合
通过@Pointcut先定义好切入点, 当通知类型可以通过被 @Pointcut 标识的方法名直接共享其切入点配置。
示例:
1 | package com.xyz.someapp; |
任何通知方法可以将第一个参数定义为org.aspectj.lang.JoinPoint类型 (环绕通知需要定义第一个参数为ProceedingJoinPoint类型, 它是 JoinPoint 的一个子类)。JoinPoint 接口提供了一系列有用的方法,比如 getArgs()(返回方法参数)、 getThis()(返回代理对象)、getTarget()(返回目标)、 getSignature()(返回正在被通知的方法相关信息)和 toString() (打印出正在被通知的方法的有用信息)。
http://shouce.jb51.net/spring/aop.html
观点仅代表自己,期待你的留言。
在MVC架构中,Controller被用于连接Model与View,同时控制View的显示与跳转。在以往的开发实践中常常是直接将View与Controller放置在同一个Project中,如果此时想要真正实现Controller与View的分离,View与Controller的交互就只能通过HTTP+数据格式或者ajax实现。那么Controller所需要做的就是将数据通过api的方式提供给View。此时针对Controller就需要将数据进行api和view的两种完全不同的视图呈现。好在Spring已经给我们提供了org.springframework.web.servlet.view.ContentNegotiatingViewResolver来实现。
spring-web.xml
1 | <!--配置消息转换器--> |
Controller.java
1 | @Controller |
以上为多视图配置的全部内容,配置中我们提供了三种视图。


useNotAcceptableStatusCode:这个配置表示,当配置为true且不能找到你需要的配置时返回HttpStatus 406. 默认值为false
首先当然是org.springframework.web.servlet.view.ContentNegotiatingViewResolver类,经过断点跟踪后,发现是通过resolveViewName()来定位的显示View。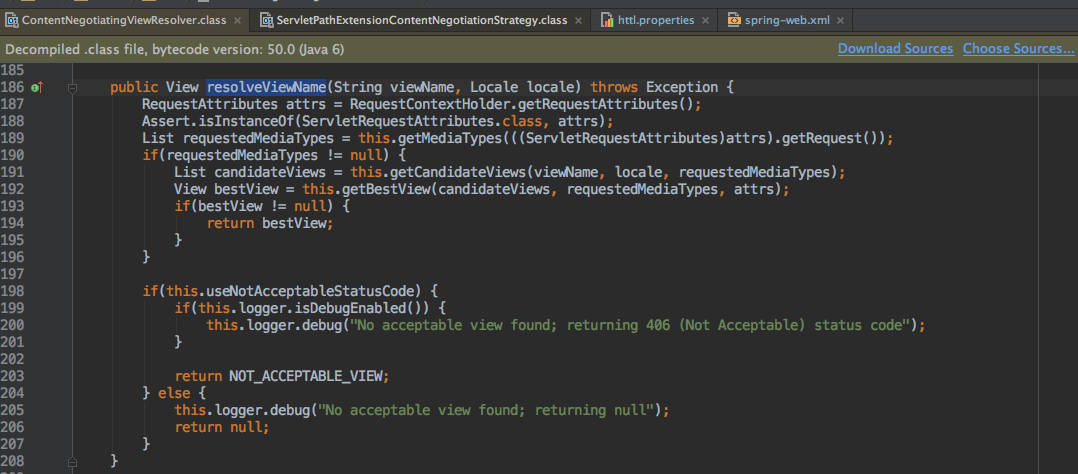
从图上可以看出,先通过request获取到requestedMediaTypes。
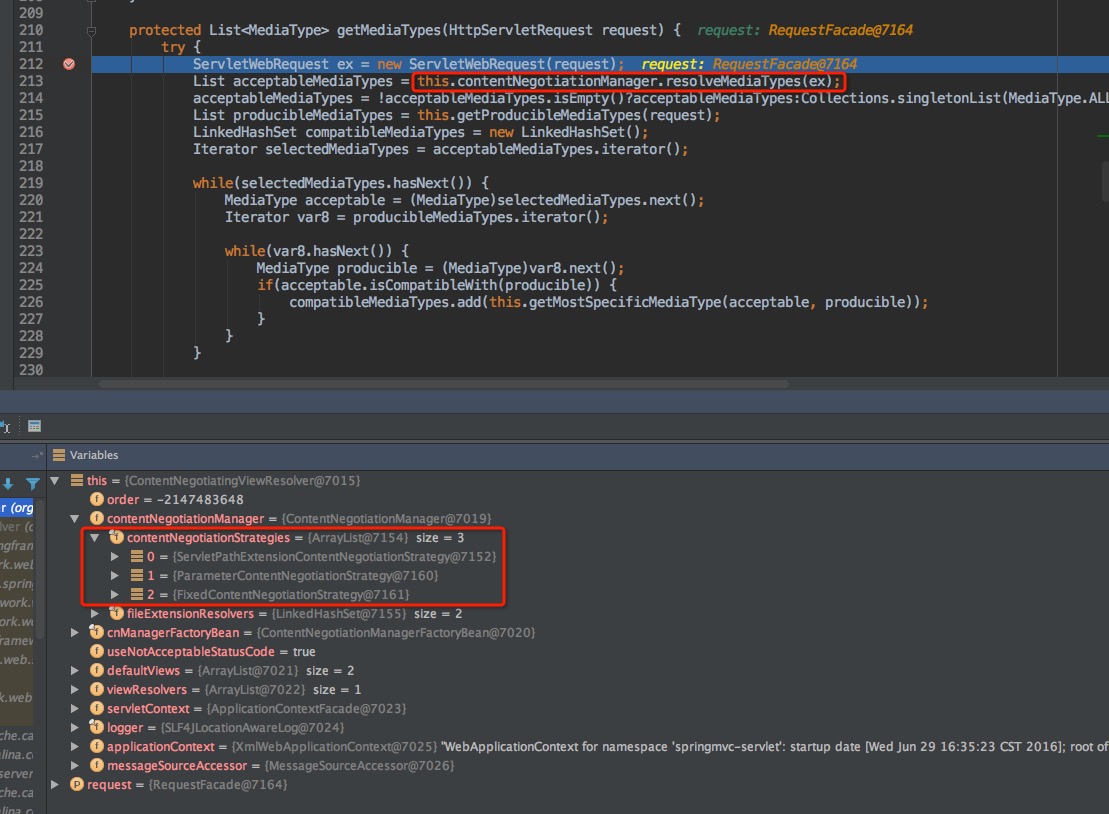
再深入一层查看,发现这里是针对requestedMediaTypes的过滤,而获取请求格式有三个途径,
ServletPathExtensionContentNegotiationStrategy(继承自PathExtensionContentNegotiationStrategy),
ParameterContentNegotiationStrategy
FixedContentNegotiationStrategy
而这恰好对应了Spring中针对识别多视图标识的配置
1 | <property name="ignoreAcceptHeader" value="true"/> |
所以可以得出结论:
1、HeaderContentNegotiationStrategy对应ignoreAcceptHeader的配置,此处配置为false,那么ContentNegotiatingViewResolver.contentNegotiationManager属性里则会多出一个元素。通过其源码可以得到它是通过在request header中增加Accept消息头获取视图格式。
2、ServletPathExtensionContentNegotiationStrategy(或者PathExtensionContentNegotiationStrategy)对应favorPathExtension的配置。通过请求后缀获取视图格式。
3、ParameterContentNegotiationStrategy对应favorParameter的配置,通过在request uri中增加format=?获取视图格式。
1 | List candidateViews = this.getCandidateViews(viewName, locale, requestedMediaTypes); |
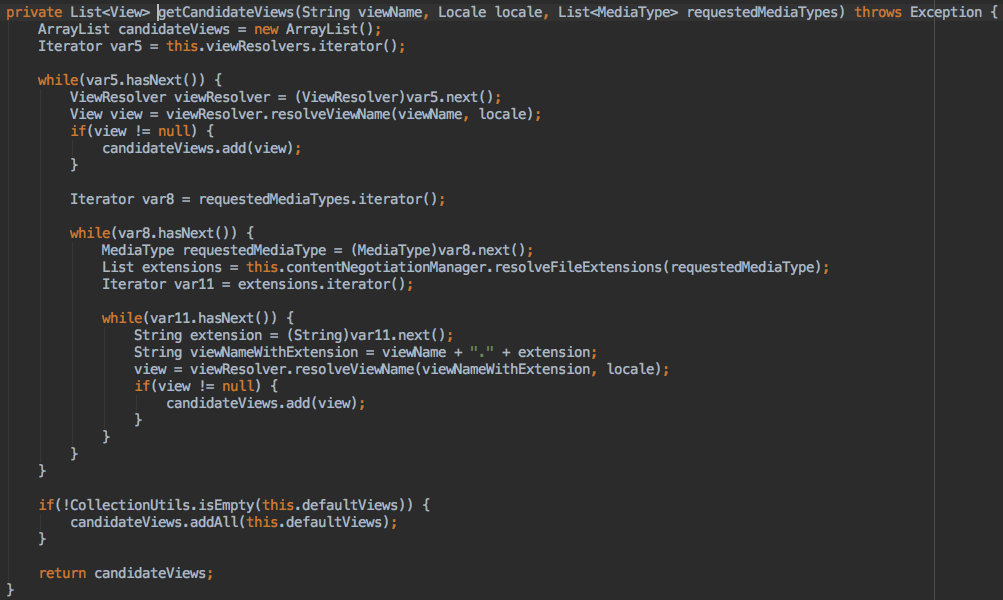
这里所做的事,就是将controller处理完成的view名称拿到配置的ViewResolver里去查找(视图名称和加了后缀的视图名称两步搜索),最后再将配置的defaultViews直接加入到返回结果的List中。此处忽略掉了视图格式标识。
1 | View bestView = this.getBestView(candidateViews, requestedMediaTypes, attrs); |
此方法所做的事:将包含视图名称的ViewResolver按requestedMediaTypes找到匹配度最高的View。
如果没有找到,则按useNotAcceptableStatusCode返回HttpCode 406.或者通过candidateViews的第一个进行视图渲染。__这里的顺序可以通过配置viewResolvers的order属性确定__。
由于在页面视图中我们需要用到很多的工具类来对Controller返回的数据进行判断以及转换等操作,所以一般来讲我们会在Map存入工具类的实例对象以便能在Page中直接使用。
但是当返回的为xml视图时,由于元素数据限制为1个,所以这些工具类将会导致多视图不能返回xml的数据格式。
在Velocity中可以配置toolbox等工具组件来实现,但是Httl并未支持。所以我找到另一个实现方式。
经过源码的查看,UrlBasedViewResolver类中包含一个staticAttributes的Map类型属性,这里完全可以拿来存放工具类对象实例,staticAttributes属性的get和set方法名称为:setAttributesMap()和getAttributesMap(). 所以配置的时候要注意配置名为__attributesMap__。
而HttlViewResolver与VelocityLayoutViewResolver都间接继承自UrlBasedViewResolver,所以可以通过配置attributesMap属性来实现工具类实例的配置。
观点仅代表自己,期待你的留言。
pom.xml
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> |
结论:由于指定插件在phase=compile时期生成源码与Javadoc,当执行完成编译后,会在target目录下生成三个文件,xxx.jar,xxx-javadoc.jar,xxx-sources.jar
观点仅代表自己,期待你的留言。